Systems Benchmarking: For Scientists and Engineers
Status:: 🟩
Links:: Performance Testing
Metadata
Authors:: Kounev, Samuel; Lange, Klaus-Dieter; Von Kistowski, Jóakim
Title:: Systems Benchmarking: For Scientists and Engineers
Date:: 2020
Publisher:: Springer International Publishing
URL:: https://link.springer.com/10.1007/978-3-030-41705-5
DOI::
Kounev, S., Lange, K.-D., & Von Kistowski, J. (2020). Systems Benchmarking: For Scientists and Engineers. Springer International Publishing. https://doi.org/10.1007/978-3-030-41705-5
Notes & Annotations
Color-coded highlighting system used for annotations
📑 Annotations (imported on 2024-04-12#12:29:04)
Definition 1.1 (Benchmark) A benchmark is a tool coupled with a methodology for the evaluation and comparison of systems or components with respect to specific characteristics, such as performance, reliability, or security.
Each benchmark is characterized by three key aspects: metrics, workloads, and measurement methodology. The metrics determine what values should be derived based on measurements to produce the benchmark results. The workloads determine under which usage scenarios and conditions (e.g., executed programs, induced system load, injected failures / security attacks) measurements should be performed to derive the metrics. finally, the measurement methodology defines the end-to-end process to execute the benchmark, collect measurements, and produce the benchmark results.
Performance: As discussed in Section 1.1, performance in its classical sense captures the amount of useful work accomplished by a system compared to the time and resources used. Typical performance metrics, which will be introduced more formally and discussed in detail in Chapter 3, include response time, throughput, and utilization.
Scalability is the ability to continue to meet performance requirements as the demand for services increases and resources are added (Smith and Williams, 2001).
Elasticity is the degree to which a system is able to adapt to workload changes by provisioning and deprovisioning resources in an autonomic manner, such that at each point in time, the available resources match the current demand as closely as possible (Herbst et al., 2013).
Energy efficiency is the ratio of performance over power consumption. Alternatively, energy efficiency can be defined as a ratio of work performed and energy expended for this work.
Availability is the readiness for correct service (Avizienis et al., 2004). In practice, the availability of a system is characterized by the fraction of time that the system is up and available to its users (Menascé et al., 2004), that is, the probability that the system is up at a randomly chosen point in time. The two main reasons for unavailability are system failures and overload conditions.
Reliability is the continuity of correct service (Avizienis et al., 2004). In practice, the reliability of a system is characterized by the probability that the system functions properly over a specified period of time (Trivedi, 2016).
Resilience encompasses all attributes of the quality of “working well in a changing world that includes faults, failures, errors, and attacks” (Vieira et al., 2012). Resilience benchmarking merges concepts from performance, dependability, and security benchmarking. In practice, resilience benchmarking faces challenges related to the integration of these three concepts and to the adaptive characteristics of the system under test.
Computer benchmarks typically fall into three general categories: specification-based, kit-based, and hybrid. Furthermore, benchmarks can be classified into synthetic benchmarks, microbenchmarks, kernel benchmarks, and application benchmarks.
Specification-based benchmarks describe functions that must be realized, required input parameters, and expected outcomes. The implementation to achieve the specification is left to the individual running the benchmark. Kit-based benchmarks provide the implementation as a required part of oficial benchmark execution. Any functional differences between products that are allowed to be used for implementing the benchmark must be resolved ahead of time. The individual running the benchmark is typically not allowed to alter the execution path of the benchmark.
Microbenchmarks are small programs used to test some specific part of a system (e.g., a small piece of code, a system operation, or a component) independent of the rest of the system. For example, a microbenchmark may be used to evaluate the performance of the floating-point execution unit of a processor, the memory management unit, or the I/O subsystem. Microbenchmarks are often used to determine the maximum performance that would be possible if the overall system performance were limited by the performance of the respective part of the system under evaluation.
Application benchmarks are complete real application programs designed to be representative of a particular class of applications. In contrast to kernel or synthetic benchmarks, such benchmarks do real work (i.e., they execute real, meaningful tasks) and can thus more accurately characterize how real applications are likely to behave. However, application benchmarks often use artificially small input datasets in order to reduce the time and effort required to run the benchmarks. In many cases, this limits their ability to capture the memory and I/O requirements of real applications. Nonetheless, despite this limitation, application benchmarks are usually the most effective benchmarks in capturing the behavior of real applications.
Benchmark designers must balance several, often conflicting, criteria in order to be successful. Several factors must be taken into consideration, and trade-offs between various design choices will influence the strengths and weaknesses of a benchmark. Since no single benchmark can be strong in all areas, there will always be a need for multiple workloads and benchmarks (Skadron et al., 2003).
The key characteristics can be organized in the following five groups:
- Relevance: how closely the benchmark behavior correlates to behaviors that are of interest to users,
- Reproducibility: producing consistent results when the benchmark is run with the same test configuration,
- Fairness: allowing different test configurations to compete on their merits without artificial limitations,
- Verifiability: providing confidence that a benchmark result is accurate, and
- Usability: avoiding roadblocks for users to run the benchmark in their test environments.
Definition 3.8 (Response Time) Response time is the time R, usually measured in seconds, it takes a system to react to a request providing a respective response. The response time includes the time spent waiting to use various resources (e.g., processors, storage devices, networks), often referred to as congestion time.
Definition 3.9 (Throughput) Throughput is the rate X at which requests are pro- cessed by a system, measured in the number of completed requests (operations) per unit of time. The throughput is a function of the load placed on the system (i.e., number of incoming requests per second) and of the maximum system capacity.
Definition 3.10 (Utilization) Utilization is the fraction of time U in which a resource (e.g., processor, network link, storage device) is used (i.e., it is busy processing requests).
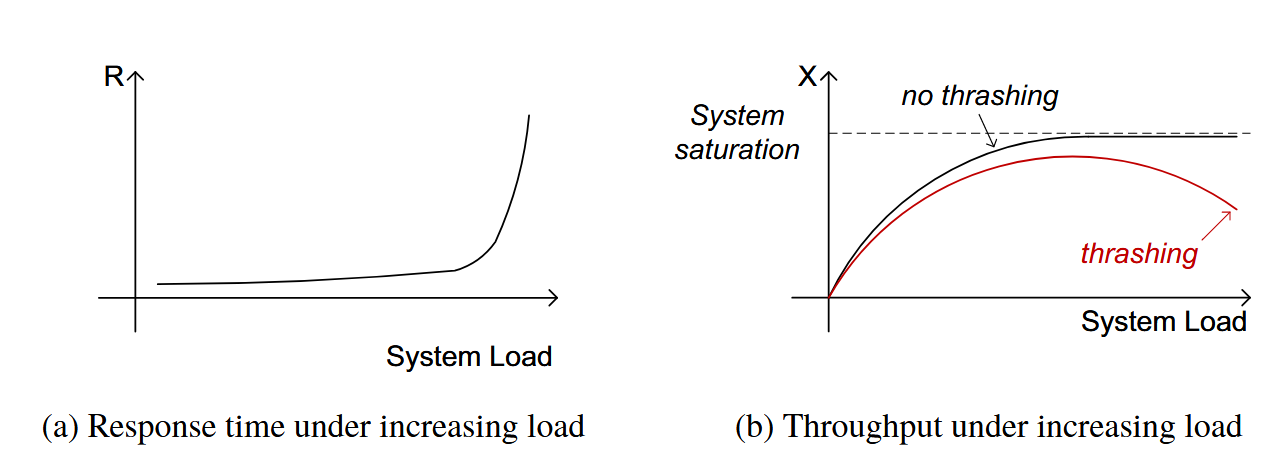
Fig. 3.1: Response time and throughput under increasing load
Figure 3.1 illustrates the behavior of the metrics response time and throughput as the load placed on the system increases. We assume a static system configuration; that is, no resources are being added using techniques such as elastic autoscaling discussed in Chapter 15. Response time rises steadily up to a given point and then increases rapidly after that. Throughput increases up to a given maximum and then either stabilizes after that or may start to slightly drop. The point at which the system throughput reaches its maximum is referred to as system saturation. Ideally, if the load increases beyond the saturation point, the system throughput should remain stable. However, in many systems, the throughput may start to drop—an effect referred to as thrashing. Thrashing is normally caused by increasing system overhead due to activities such as memory paging or contention for software resources (e.g., database locks, operating system threads, network connections).
Batch Workload: A batch workload is a workload consisting of a single, usually long-running, executable work unit. A batch workload is run once until it completes or its execution is halted. Batch workloads lend themselves well (but not exclusively) to being used as a basis for building fixed-work benchmarks
Transactional Workload: A transactional workload consists of small work units that are repeated multiple times during the execution of a benchmark. Each execution of such a work unit is referred to as a transaction. The workload may consist of multiple transaction types that are interwoven or run in parallel. Transactional workloads lend themselves well (but not exclusively) to being used as a basis for building fixed-time benchmarks

Basic Energy-efficiency Metric
The SPECpower_ssj2008 benchmark was developed by the SPEC OSG Power Committee and was the first industry-standard benchmark to measure the energy efficiency of servers. It was developed in conjunction with the initial version of the SPEC Power and Performance Benchmark Methodology and served both as the basis for developing the first draft of the methodology and as its first implementation. The lessons learned during the development of the benchmark were incorporated into the methodology. The benchmark was based on the earlier SPECjbb2005 benchmark, which was a Java implementation of a simple OLTP workload. In SPECpower_ssj2008 the workload was modified to run at ten different load levels (100%, 90%, ..., 10%) as well as an active idle measurement, rather than only measuring performance at full utilization like its predecessor.
The presented experiments use an increasing load intensity profile as part of the workload description discussed in the previous section. The load profile starts at eight requests per second and increases to 2,000 requests per second over the time of 4 min. The request content is specified using the user browse profile for the 128 users accessing the store. Depending on the current SUT configuration, some of the 4 min are spent in a state in which the load intensity exceeds the capacity of the SUT. The power consumption of the physical servers and the throughput of TeaStore are measured during the entire run. However, only measurements made during the time in which workload arrives at the system are taken into account. Each measurement is taken on a per-second basis and thus tightly coupled to the current load intensity.
Definition 16.2 (Performance Isolation) Performance isolation is the ability of a system to ensure that tenants working within their assigned quotas (i.e., abiding tenants) will not suffer performance degradation due to other tenants exceeding their quotas (i.e., disruptive tenants).