Data management in microservices: state of the practice, challenges, and research directions
Status:: 🟩
Links:: Data Consistency in Distributed Systems
Metadata
Authors:: Laigner, Rodrigo; Zhou, Yongluan; Salles, Marcos Antonio Vaz; Liu, Yijian; Kalinowski, Marcos
Title:: Data management in microservices: state of the practice, challenges, and research directions
Publication Title:: "Proceedings of the VLDB Endowment"
Date:: 2021
URL:: https://dl.acm.org/doi/10.14778/3484224.3484232
DOI:: 10.14778/3484224.3484232
Laigner, R., Zhou, Y., Salles, M. A. V., Liu, Y., & Kalinowski, M. (2021). Data management in microservices: State of the practice, challenges, and research directions. Proceedings of the VLDB Endowment, 14(13), 3348–3361. https://doi.org/10.14778/3484224.3484232
Microservices have become a popular architectural style for data-driven applications, given their ability to functionally decompose an application into small and autonomous services to achieve scalability, strong isolation, and specialization of database systems to the workloads and data formats of each service. Despite the accelerating industrial adoption of this architectural style, an investigation of the state of the practice and challenges practitioners face regarding data management in microservices is lacking. To bridge this gap, we conducted a systematic literature review of representative articles reporting the adoption of microservices, we analyzed a set of popular open-source microservice applications, and we conducted an online survey to cross-validate the findings of the previous steps with the perceptions and experiences of over 120 experienced practitioners and researchers.
Through this process, we were able to categorize the state of practice of data management in microservices and observe several foundational challenges that cannot be solved by software engineering practices alone, but rather require system-level support to alleviate the burden imposed on practitioners. We discuss the shortcomings of state-of-the-art database systems regarding microservices and we conclude by devising a set of features for microservice-oriented database systems.
Notes & Annotations
Color-coded highlighting system used for annotations
📑 Annotations (imported on 2024-01-17#12:19:55)
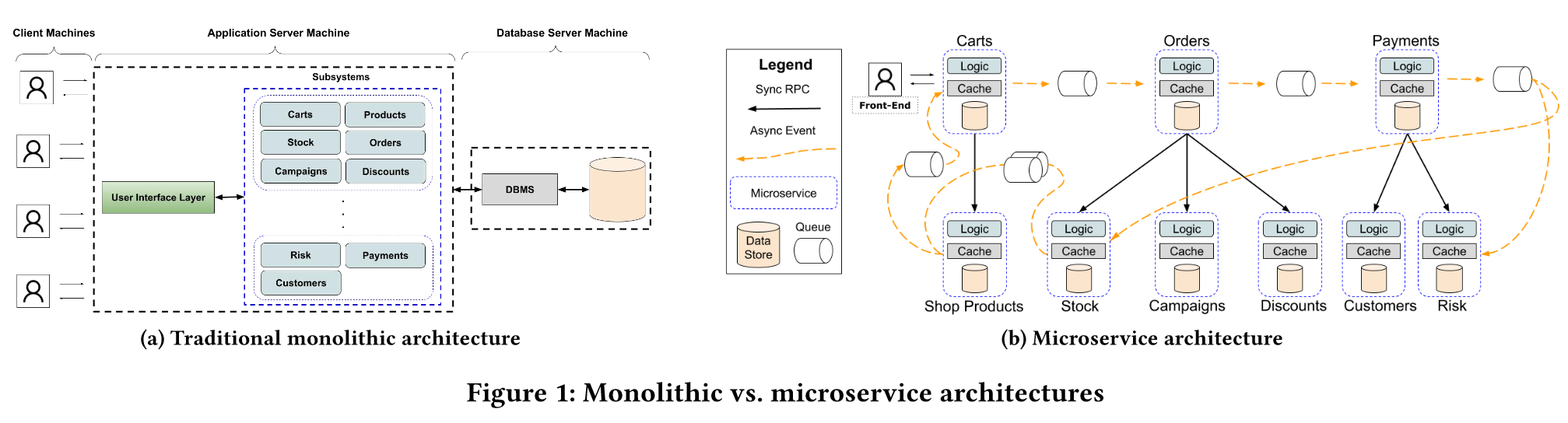
In contrast to a monolithic architecture (Figure 1(a)), where modules and/or subsystems are integrated and cooperate in a centralized manner, a microservice architecture, (Figure 1(b)), organizes an application as a set of small services that are built, deployed, and scaled independently.
In the monolithic case, to process an order, for example, the Cart module performs a function call to the Order module, which then performs additional function calls to the Stock, Campaigns, and Discounts modules to safeguard the order is correctly placed. In contrast to direct function calls between modules, microservices communicate with each other through remote calls, such as HTTP-based protocols [20, 24] or asynchronous messages [83].
In particular, in the monolithic architectural style, transactions can be easily executed across modules, while, in microservices, it becomes necessary to break these transactions down due to the decomposition of the application into small parts.
Despite the increased adoption of microservices in industry settings [2, 14, 27, 28, 37, 43, 45, 46, 61] and the perception that data management is a major challenge in microservices [22, 36, 44, 65, 77, 82], there is little research on the characteristics of data management in microservices in practice.
From 300 peer-reviewed articles analyzed, 10 representative articles [2, 12, 14, 28, 37, 38, 45, 46, 61, 76] were selected for review; (ii) we analyze 9 popular microservice-based applications [1, 18, 34, 48, 49, 62, 63, 66, 79], selected out of more than 20 open-source projects, and; (iii) we design an online survey to gather the opinions of developers and researchers experienced with microservices in real-world settings, allowing us to cross-validate the findings of the previous steps. In total, more than 120 practitioners provided important information about their microservices’ deployments in industry settings.
From our investigation, we observed that microservice developers are dealing with a plethora of data management challenges. While microservices are supposed to work autonomously, they often surprisingly end up exhibiting functionality and private state dependencies amongst each other.
Practitioners are poorly served by state-of-the-art database systems (DBMSs) and end up weaving together several heterogeneous data systems such as message brokers, in-memory caches, analytical engines, and loosely structured and structured DBMSs in an ad-hoc manner. This system complexity leads to a substantial amount of data management logic at the application layer to meet the data management requirements of microservices.

although some studies described related pitfalls, such as shared persistence [57, 69], and previous literature investigated architectural smells and anti-patterns in microservices [9, 51, 70, 72], they fail to capture properties of consistency models and technical issues of database systems, such as data replication and constraint enforcement, as we provide in this paper.
[57] Ilaria Pigazzini, Francesca Arcelli Fontana, Valentina Lenarduzzi, and Davide Taibi. 2020. Towards Microservice Smells Detection. In Proceedings of the 3rd International Conference on Technical Debt (Seoul, Republic of Korea) (TechDebt ’20). Association for Computing Machinery, New York, NY, USA, 92–97. https://doi.org/10.1145/3387906.3388625
[69] D. Taibi and V. Lenarduzzi. 2018. On the Definition of Microservice Bad Smells. IEEE Software 35, 3 (2018), 56–62.
Our results indicate that functional decomposition, fault isolation, schema evolution, and event-driven architecture are the primary reasons behind the adoption of microservices for data management.
There are three mainstream approaches for using database systems in microservice architectures: (i) private tables per microservice, sharing a database server and schema; (ii) schema per microservice, sharing a common database server; and (iii) database server per microservice [47].
[47] Antonio Messina, Riccardo Rizzo, Pietro Storniolo, Mario Tripiciano, and Alfonso Urso. 2016. The Database-is-the-Service Pattern for Microservice Architectures, Vol. 9832. 223–233. https://doi.org/10.1007/978-3-319-43949-5_18
The results suggest that microservices are prevalently deployed in individual containers, predominantly using the database-per-microservice pattern to achieve performance and fault isolation
Regarding business transactions across microservices, 1 conversations (i.e., the interaction between a set of consumer and producer services) are prevalent. Hohpe [31] argues that orchestration and choreography are the two types of interactions that take place in the context of distributed web applications. Most papers [2, 28, 37, 38, 45, 46, 61] and open-source projects [1, 18, 34, 48, 62, 63, 66, 79] report the use of the choreography conversation pattern [31] through both synchronous and asynchronous event-based workflows.
[31] Gregor Hohpe. 2007. Let’s have a conversation. IEEE internet computing 11, 3 (2007), 78–81.
This finding has led us to observe that microservice architectures indeed follow the BASE model [59], which targets functionally decomposing an application to achieve higher scalability in exchange for a weak consistency model.
[59] Dan Pritchett. 2008. Base: An Acid Alternative. In File Systems and Storage, Vol. 6. ACM Queue. Issue 3.
Besides, some papers report the use of orchestration [2, 12, 14]. Only one open-source project [49] adopts a saga-like orchestration.
[49] microservices patterns. [n.d.]. ftgo-application. https://github.com/microservices-patterns/ftgo-application
While the literature [20, 52, 83] mentions the principle that microservices are autonomous components that are independently deployed and evolved, we observed that most microservice-based applications often perform operations that span multiple microservices (Figure 2 and Table 2), which indicates a functionality dependence between microservices.

In contrast with findings from literature and open-source repositories, orchestration-like (including sagas [25] and the back-end for front-end pattern (BFF) [8, 53, 74]) mechanisms are the most popular in industry settings.
[25] Hector Garcia-Molina and Kenneth Salem. 1987. Sagas. SIGMOD Rec. 16, 3 (Dec. 1987), 249–259. https://doi.org/10.1145/38714.38742
[8] Phil Calçado. 2015. The Back-end for Front-end Pattern (BFF). Retrieved September 10, 2020 from https://philcalcado.com/2015/09/18/the_back_end_for_front_end_pattern_bff.html
[53] Sam Newman. 2015. Pattern: Backends For Frontends. Retrieved July 6, 2021 from https://samnewman.io/patterns/architectural/bff/
[74] Miguel Veloso. 2019. BFF implementation. Retrieved July 6, 2021 from https://github.com/dotnet-architecture/eShopOnContainers/wiki/BFF-implementation
The results highlight that the adoption of custom-made (e.g., company-built) orchestration engines is prevalent among participants (51.2%).
We also asked the participants to briefly describe one of their use cases involving consistency in operations spanning multiple microservices. 32 out of 90 (35.5%) responded and most responses (78%) indicated the implementation of workflows through application code and the use of application-level validations to safeguard the constraints of the workflow.
The results suggest the prominence of orchestration-like mechanisms in industry settings, in contrast to the prevalence of choreography in the open-source repositories. Additionally, 2PC is not used often, while asynchronous and event-based coordination is the norm.
The results highlight that the decentralized data management principle does not refrain microservices from performing queries over distributed states. As a result, practitioners often rely on ad-hoc mechanisms for data processing at the application level.
In the absence of efficient or viable solutions for isolation guarantees in the application-tier, microservice developers are exposed to concurrency anomalies. This creates a great barrier for expressing correctness criteria across different microservices.
Developers have no support for querying multiple microservice database states consistently and they end up encountering challenges on reasoning about the application state.
The lack of comprehensive support for data replication across microservices lead developers to rely on ad-hoc application-level replication mechanisms, a choice that often leads to inconsistency among microservice states.
Due to the distributed nature of microservice architectures, eventual consistency is often taken as the de facto consistency model by practitioners. This choice introduces a series of challenges on reasoning about distributed states and invariants.
“microservices made people separate code when they should not be separated, causing this eventual consistency everywhere. [...] people wanted to create a separate microservice, just because of ‘size’, and we end up having consistency problems.”
The lack of a benchmark that properly reflects real-world deployments refrains developers from effectively experimenting with and reasoning about microservice deployments.
there have been several recent works in Internetscale database services. These systems provide high availability at a global scale, at the same time offering high throughput data processing and multi-tenancy by design. While some of them support strong consistency guarantees, such as Google Spanner [13], Amazon Aurora [75], and Azure Cosmos DB [3], others trade stronger consistency for performance, such as DynamoDB [16] and Astra DB [67].